Readings: functions and methods for lists and tuples
Contents
5.3. Readings: functions and methods for lists and tuples#
5.3.1. Unpacking sequences of variables#
So far we have seen how to group different variables or values into a single variable. By unpacking we reverse this process: we move from one sequence of variables to multiple variables. This is really useful when you want to take one or more items from a sequence and assign them to new variable(s) that can call later.
The syntax for unpacking looks like this:
var1, var2, var3, .... = sequence_name
On the left-hand side there should be as many variable names as there are elements in the sequence in the right-hand side. For example:
fermented_drinks = ['wine', 'beer', 'cider', 'yoghurt']
drink1, drink2, drink3, drink4 = fermented_drinks
print(drink1, drink2, drink3, drink4)
wine beer cider yoghurt
As you can see, each variable is assigned a value from the list. The same can happen with tuples:
fermented_foods = ('kimchi', 'sauerkraut', 'kefir')
food1, food2, food3 = fermented_foods
print(food1, food2, food3)
kimchi sauerkraut kefir
To avoid the need to declare as many variables as there are elements in a list or tuple, you can declare variables for the values you need and then declare other variables with a preceding asterisk (*) that will collect all the remaining elements in a list:
drink1, *the_rest = fermented_drinks
print(drink1, the_rest)
wine ['beer', 'cider', 'yoghurt']
As you can see, all the remaining elements are collected into a list. This can be applied to tuples as well:
food1, *the_other = fermented_foods
print(food1, the_other)
kimchi ['sauerkraut', 'kefir']
Depending on the position of items we want to single out and save in a variable, we should specify where the variable with the asterisk should stand. For example, if we would like to save the first and last elements of the fermented_drinks list then we would do:
drink1, *the_rest, drink4 = fermented_drinks
print(drink1, the_rest, drink4)
wine ['beer', 'cider'] yoghurt
Also, if we would like to store only the last element, then we would write:
*the_rest, drink4 = fermented_drinks
print(the_rest, drink4)
['wine', 'beer', 'cider'] yoghurt
Similarly, if we would like to single out only the last two values we would write:
*the_rest, drink3, drink4 = fermented_drinks
print(the_rest, drink3, drink4)
['wine', 'beer'] cider yoghurt
As you can see, the position of the_rest variable is flexible based on what we need to isolate.
5.3.1.1. enumerate() function#
The enumerate() function is a built-in function in Python used to iterate over sequences of values. It is a more elegant way than the previously used range() function since it avoids any IndexErrors. It receives as argument a sequence of values (iterable) and for each element in the list it returns a tuple consisting of (key, value) pairs where the key is the index and the value is the element in an iterable corresponding to that index. The function itself produces an object of type enumerate. If we directly use the print() function on it, then it will print the memory location of this object. To print its contents element-by-element, we need to add * before the enumerate call:
print(*enumerate(fermented_drinks))
(0, 'wine') (1, 'beer') (2, 'cider') (3, 'yoghurt')
Similarly we can iterate over the tuples using a for-loop:
for i, tuple_i in enumerate(fermented_drinks):
print(f'Index: {i} ->\tdrink: {tuple_i}')
Index: 0 -> drink: wine
Index: 1 -> drink: beer
Index: 2 -> drink: cider
Index: 3 -> drink: yoghurt
5.3.2. Slicing#
As we saw in Accessing elements in lists and Accessing elements in tuples, we can use slicing to access a range of values. Here we will see some more specific cases of slicing.
5.3.2.1. Slicing with step size#
fermented_drinks = ['wine', 'beer', 'cider', 'yoghurt']
fermented_drinks[1:4:2]
['beer', 'yoghurt']
The third number says that we are going to select only every second index. For example, in this case, since we are interested in the range [1:4) with a step size of 2, from {1,2,3} we are going to select only {1,3}.
We can also use negative indices and step sizes. Look at the example below:
fermented_drinks[-1:-4:-2]
['yoghurt', 'beer']
Here we process the list of fermented_drinks in reverse order from the last item indexed at position -1 until the first item indexed at position -4 (for a visual explanation on how negative indices work check Fig. 5.2) going backward 1 element each time.
5.3.2.2. Modifying lists using slicing#
We can modify many list elements in one go using slicing as well.
print('Before:', fermented_drinks)
fermented_drinks[1:4] = ['wine','wine','wine']
print('After:', fermented_drinks)
Before: ['wine', 'beer', 'cider', 'yoghurt']
After: ['wine', 'wine', 'wine', 'wine']
As you can see, all elements from positions {1,2,3} were substituted with the elements of the new list (3 X wine).
5.3.3. zip() function#
The zip() function allows us to concatenate elements from different iterables into tuples. For example, if we have a list of chemical elements and another one of their respective atomic numbers, then we can use the zip() function to form tuples containing the chemical elements and their atomic number:
chemical_elements = ['O', 'Ca', 'C', 'Na', 'K']
atomic_numbers = [8, 20, 6, 11, 19]
print(*zip(chemical_elements, atomic_numbers))
('O', 8) ('Ca', 20) ('C', 6) ('Na', 11) ('K', 19)
Or we can iterate over the two lists simultaneously:
for element in zip(chemical_elements, atomic_numbers):
print(element)
('O', 8)
('Ca', 20)
('C', 6)
('Na', 11)
('K', 19)
Important
If the lists we are trying to zip do not have the same number of elements, then the zipped sequence will have as many tuples as the number of elements of the smallest list.
5.3.4. del statement#
The del keyword can be used to delete any variables from the workspace or to delete any elements in lists. For example:
fermented_foods = [
'sauerkraut', 'kefir', 'kimchi', 'kombucha', 'yoghurt', 'cheese'
]
#delete the last element
del fermented_foods[-1]
fermented_foods
['sauerkraut', 'kefir', 'kimchi', 'kombucha', 'yoghurt']
# delete a range of values
del fermented_foods[2:5] # 5 non-inclusive
fermented_foods
['sauerkraut', 'kefir']
# delete the list completely
del fermented_foods
fermented_foods
---------------------------------------------------------------------------
NameError Traceback (most recent call last)
Cell In[19], line 3
1 # delete the list completely
2 del fermented_foods
----> 3 fermented_foods
NameError: name 'fermented_foods' is not defined
After trying to execute the last statement to print the fermented_foods list, we will get a NameError since the variable does not exist anymore in the workspace.
Important
We cannot use del keyword to remove an item or a range of items from a tuple because tuples are immutable. However, the del keyword can be used to remove the tuple entirely from the workspace by deleting it.
5.3.5. Passing lists and tuples to functions#
All arguments passed to functions are passed by reference. This means that the function can access directly the memory locations of the passed arguments, thus any changes done to the arguments will be reflected anywhere in the program when the arguments will be accessed after the function call.
5.3.5.1. Passing tuples to functions#
Passing tuples to functions as arguments means that the function is accessing directly the memory space of the tuple. If you refer to Fig. 5.4, the function will have access directly to the space enclosed in the red rounded square. As we saw in the previous section, tuples are immutable so no changes can happen to this area. If the tuple elements are undergoing changes inside a function then an error will be thrown and the program will stop executing.
Important
Keep in mind that if inside the function we try to modify mutable objects of the tuple, then no errors will occur for the same reasons as explained in Modifying elements of a tuple.
Let us look at an example:
def subtract_two(sequence_of_values):
for index, value in enumerate(sequence_of_values):
sequence_of_values[index] -= 2
tuple_of_numbers = (0,1,2,3,4,5)
subtract_two(tuple_of_numbers)
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
/var/folders/7f/7nw_x13n5q965rss_qz6061m0000gq/T/ipykernel_53847/2895445588.py in <module>
1 tuple_of_numbers = (0,1,2,3,4,5)
----> 2 subtract_two(tuple_of_numbers)
/var/folders/7f/7nw_x13n5q965rss_qz6061m0000gq/T/ipykernel_53847/631423467.py in subtract_two(sequence_of_values)
1 def subtract_two(sequence_of_values):
2 for index, value in enumerate(sequence_of_values):
----> 3 sequence_of_values[index] -= 2
TypeError: 'tuple' object does not support item assignment
As you can see, the above code throws a TypeError since it is impossible to modify tuple elements. So we should be careful when we access tuples inside a function. We can use its values in calculations but we cannot change them.
5.3.5.2. Passing lists to functions#
Passing lists as arguments to functions does not make any difference in terms of what the function sees. Again the list is passed by reference so the function has direct access to the memory space of the list. This means that any changes that happen to the list elements inside the function will be reflected in the original list after the flow of control returns from the function call. Note that since lists are mutable there are no problems with modifying elements residing on the list memory space. (Again, for clarity on the memory space refer to Fig. 5.4.)
We will provide an example by using the subtract_two function defined above:
list_of_numbers = [0,1,2,3,4,5]
subtract_two(list_of_numbers)
list_of_numbers
[-2, -1, 0, 1, 2, 3]
As you can see, the changes are directly applied to the original elements of the list. This is something that should be considered carefully when writing code because it is one of the most common logical mistakes that might be difficult to notice.
5.3.5.3. Copying lists (Shallow vs Deep Copying)#
In order to avoid any mistakes introduced in the code when we pass lists to functions we might create a copy of the list and work with the copy instead of the original list. However, there are two types of copies of a list: a shallow copy and a deep copy. A shallow copy of a list is another list that points to the same memory space as the original one. All the changes that happen to the original or to the shallow copy will be seen by the other. On the other hand, a deep copy of the list consist of creating a completely new list from an existing one. The elements of the old list will be copied into the memory space of the new list. Changes made to any of the lists are not reflected in the other.
Fig. 5.6 shows the memory changes when a shallow copy of a list is created. As you can see, elements are not copied but the copy will just point to the same address as the original one. Any changes that will be made to the original or the copy will be reflected in the other one.

Fig. 5.6 Shallow copy of lists#
The example below illustrates a shallow copy of a list:
numbers = [0,1,2,3,4,5]
numbers_copy = numbers
print('Original:', numbers)
print('Copy:', numbers_copy)
#changing some elements
numbers[1]=2
numbers_copy[3] = 6
print('Original after changes:', numbers)
print('Copy after changes:', numbers_copy)
Original: [0, 1, 2, 3, 4, 5]
Copy: [0, 1, 2, 3, 4, 5]
Original after changes: [0, 2, 2, 6, 4, 5]
Copy after changes: [0, 2, 2, 6, 4, 5]
As you can see, although changes happened in only one of the lists, they were reflected in the other one, too. This is a side effect of sharing the same area in memory.
Fig. 5.7 shows what happens when we do a deep copy of a list. As you can see, the lists are completely uncoupled and distinct. The only thing that they have in common are the element values. But they have their own space in memory. If one of the lists changes, the other one remains unchanged.
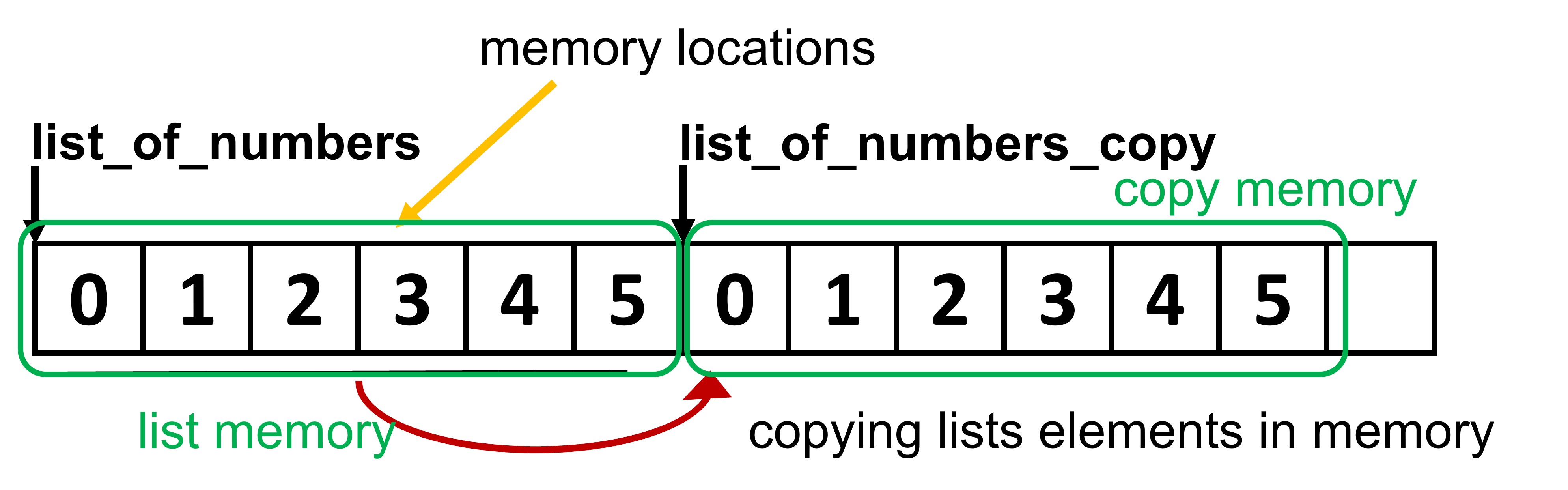
Fig. 5.7 Deep copy of lists#
The example below shows a deep copy of a list:
numbers = [0,1,2,3,4,5]
numbers_copy = list(numbers)
print('Original:', numbers)
print('Copy:', numbers_copy)
#changing some elements
numbers[1]=2
numbers_copy[3] = 6
print('Original after changes:', numbers)
print('Copy after changes:', numbers_copy)
Original: [0, 1, 2, 3, 4, 5]
Copy: [0, 1, 2, 3, 4, 5]
Original after changes: [0, 2, 2, 3, 4, 5]
Copy after changes: [0, 1, 2, 6, 4, 5]
As you can see, changes now are localized and they affect only the list where they are applied. This enforces the idea that the two lists do not share the same memory space.
5.3.6. 2D lists#
2D lists are nothing more than lists of lists: each element of a list is a list. For example:
two_dim_list = [[1,2,3], # first row
[4,5,6], # second row
[7,8,9]] # third row
A 2D dimensional list’s elements (which are lists themselves) can have the same number of elements or different number of elements.
To access the elements of a 2D list we use two indices: the first one for the row and the second one for the column. To understand this, let us look at a tabular representation of the two_dim_list:
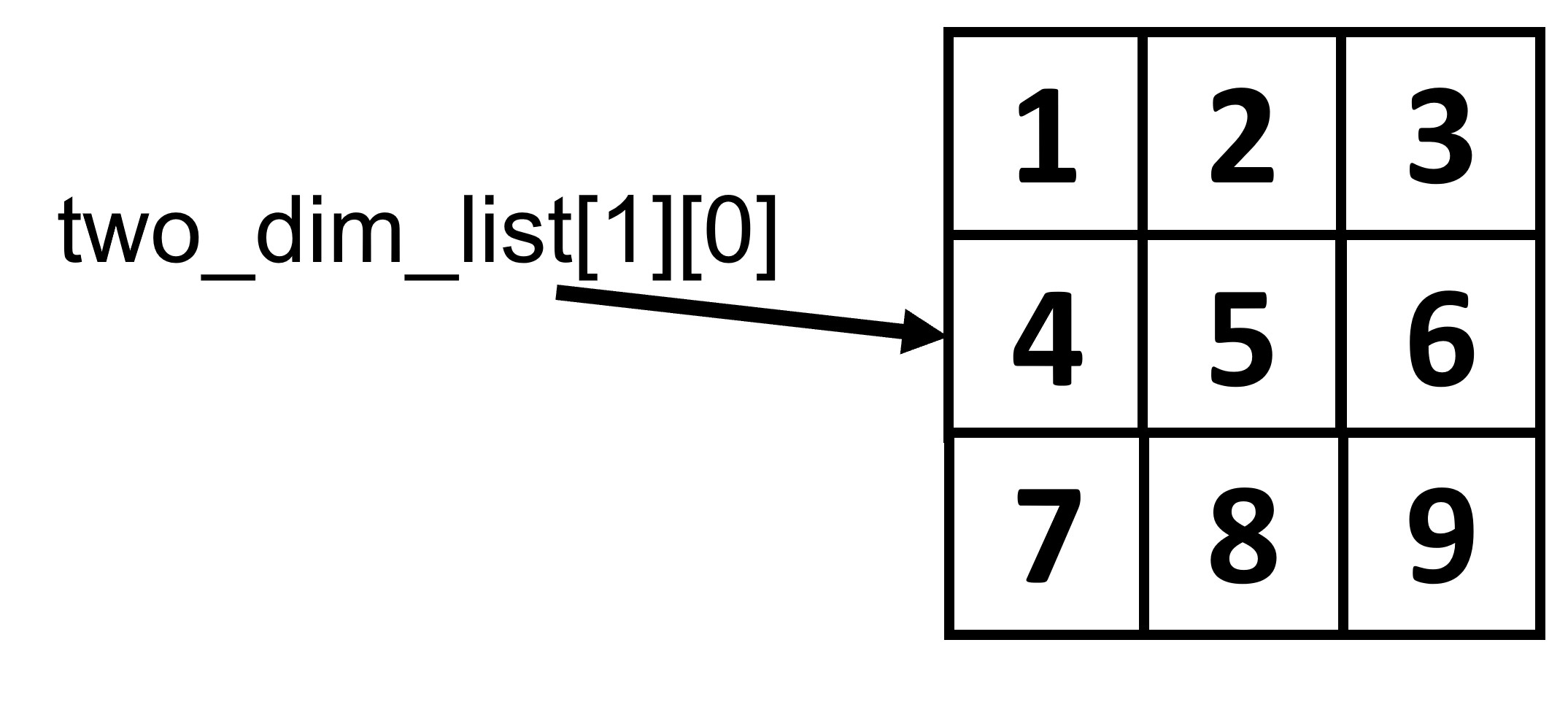
Fig. 5.8 Two dimensional lists#
Usually the row index is indicated by i and the column index by j.
To print element 5 from the two_dim_list we would write:
two_dim_list[1][1]
5
To print all the values in a tabular format we can use two nested for-loops:
for i in range(0, len(two_dim_list)):
for j in range(0, len(two_dim_list[i])):
print(two_dim_list[i][j], end=' ')
print()
1 2 3
4 5 6
7 8 9
The outer for-loop is responsible for iterating over the rows while the inner for-loop for iterating over the columns of each row.
5.3.7. Functional style programming (Optional)#
Functional style programming refers to programming practices where the programmer specifies via code what the computer should run, but how the task will be accomplished is determined by the computer. On the other hand in imperative style programming, the programmer explicitly specifies the steps that a program should follow in order to accomplish a certain task.
An example of functional style programming is list-comprehension. Below we will see two more examples related to filter() and map() built-in functions. A distinct feature of functional-style programming is the ability to pass functions as arguments to functions.
5.3.7.1. Lambda expressions#
Lambda expressions are in-line functions. Otherwise they are called anonymous functions since they do not have a name. The syntax for a lambda expression is:
lambda parameters: expression
This is equivalent to specifying a function like:
def function(parameters):
return expression
For example, we can define a function that will receive a number and will determine if it is a multiple of 3 or not:
def is_divisible_by_3(num):
return num%3==0
Using lambda expression this would be written as:
lambda num: num%3==0
However, lambda expressions as standalone expressions are of no help. That’s why they are used inside other functions, for example those used to do filtering or mapping.
5.3.7.2. Filter#
Suppose that we have a list of numbers and we want to find which values are multiples of 3. One way to do this is by explicitly using the is_divisible_by_3() function defined above in a list comprehension:
numbers = [1,2,3,4,5,6,7,8,9]
[mult_3 for mult_3 in numbers if is_divisible_by_3(mult_3)]
[3, 6, 9]
A second way is to use the built-in filter() function and pass there as first argument the function that will be used for filtering and as second argument the list that we are going to filter. The filter() function returns a sequence of values. For example:
list(filter(is_divisible_by_3, numbers))
[3, 6, 9]
In English this means: go over each element of the numbers list and save the element if is_divisible_by_3 evaluates to True, otherwise ignore it.
Another way is to use a lambda expression with the built-in filter() function:
list(filter(lambda num: num%3==0, numbers))
[3, 6, 9]
As you can see, the first argument which was the function value is now substituted by the lambda expression. Here we specify what we want the program to do, but not how it should be executed. We do not determine any looping strategy for going over the list - we only specify the condition of filtering and the list that we want to filter, the rest is in the computer’s hands. What happens is this: the numbers list is iterated once and each element is checked against the condition in the lambda expression, if the condition evaluates to True then that element is saved in the list, otherwise it is ignored.
5.3.7.3. Map#
Similarly to the built-in filter() function is the map() function. It maps a sequence of values to another sequence of values. For example, if we want to create a list of the doubles of the numbers list from the previous section then we would write:
list(map(lambda x: x*2, numbers))
[2, 4, 6, 8, 10, 12, 14, 16, 18]
Just like with the filter() function, it takes two arguments: a function or the equivalent lambda expression and a sequence of values. Then it applies the lambda expression to the sequence of values and everything is collected in a list.
It is possible to chain filter() and map() outputs and to produce a result. See Exercises.